Latest News
- Home
- Blog

 By Adrian Tam
By Adrian Tam Preparing Data for BERT Training
This article is divided into four parts; they are: • Preparing Documents • Creating Sentence Pairs from Document • Masking Tokens • Saving the Training Data for Reuse Unlike decoder-only models,...
Read More...
The Complete Guide to Docker for Machine Learning Engineers
Machine learning models often behave differently across environments.
Read More...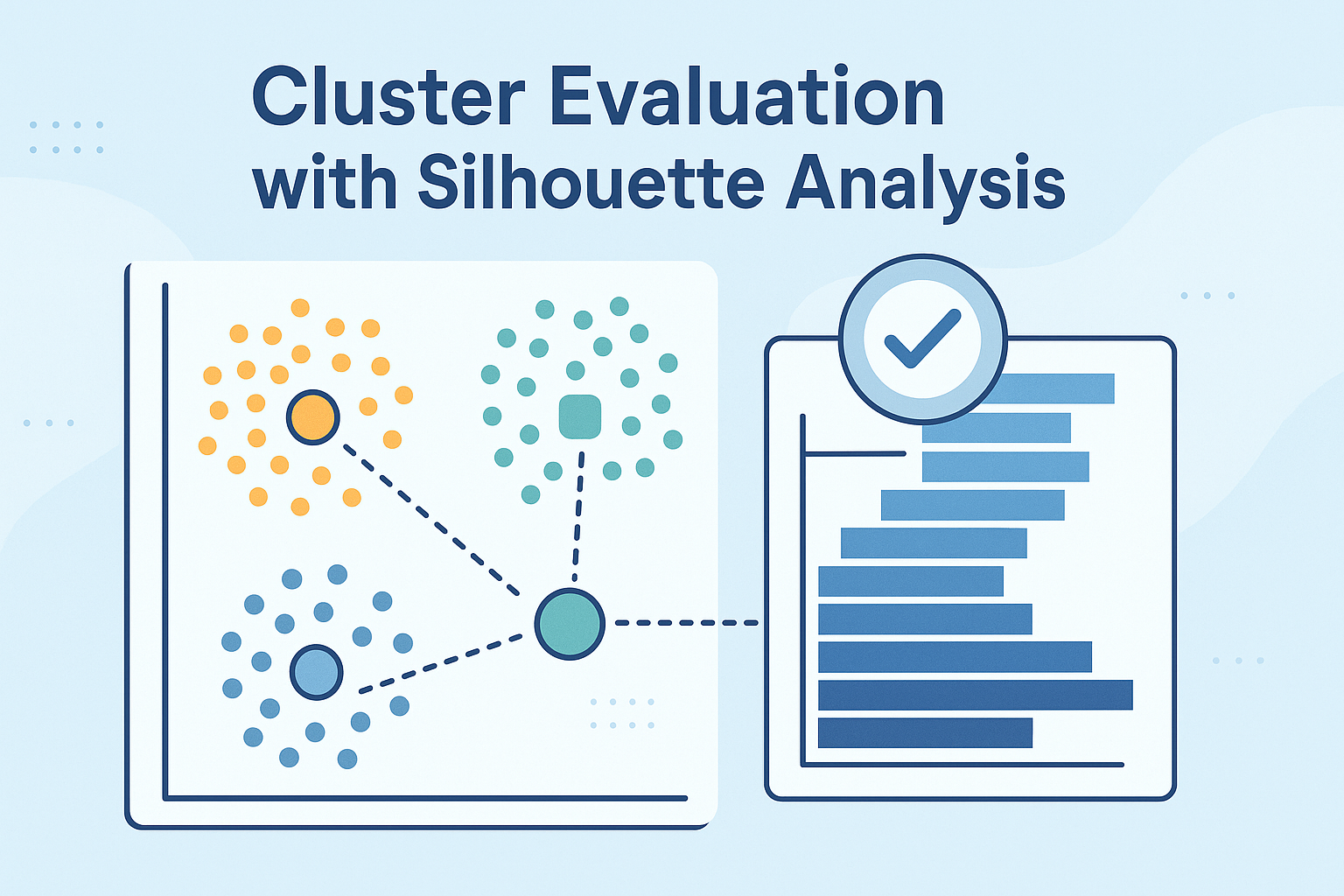
K-Means Cluster Evaluation with Silhouette Analysis
Clustering models in machine learning must be assessed by how well they separate data into meaningful groups with distinctive characteristics.
Read More...
Pretrain a BERT Model from Scratch
This article is divided into three parts; they are: • Creating a BERT Model the Easy Way • Creating a BERT Model from Scratch with PyTorch • Pre-training the BERT Model If your goal is to create a...
Read More...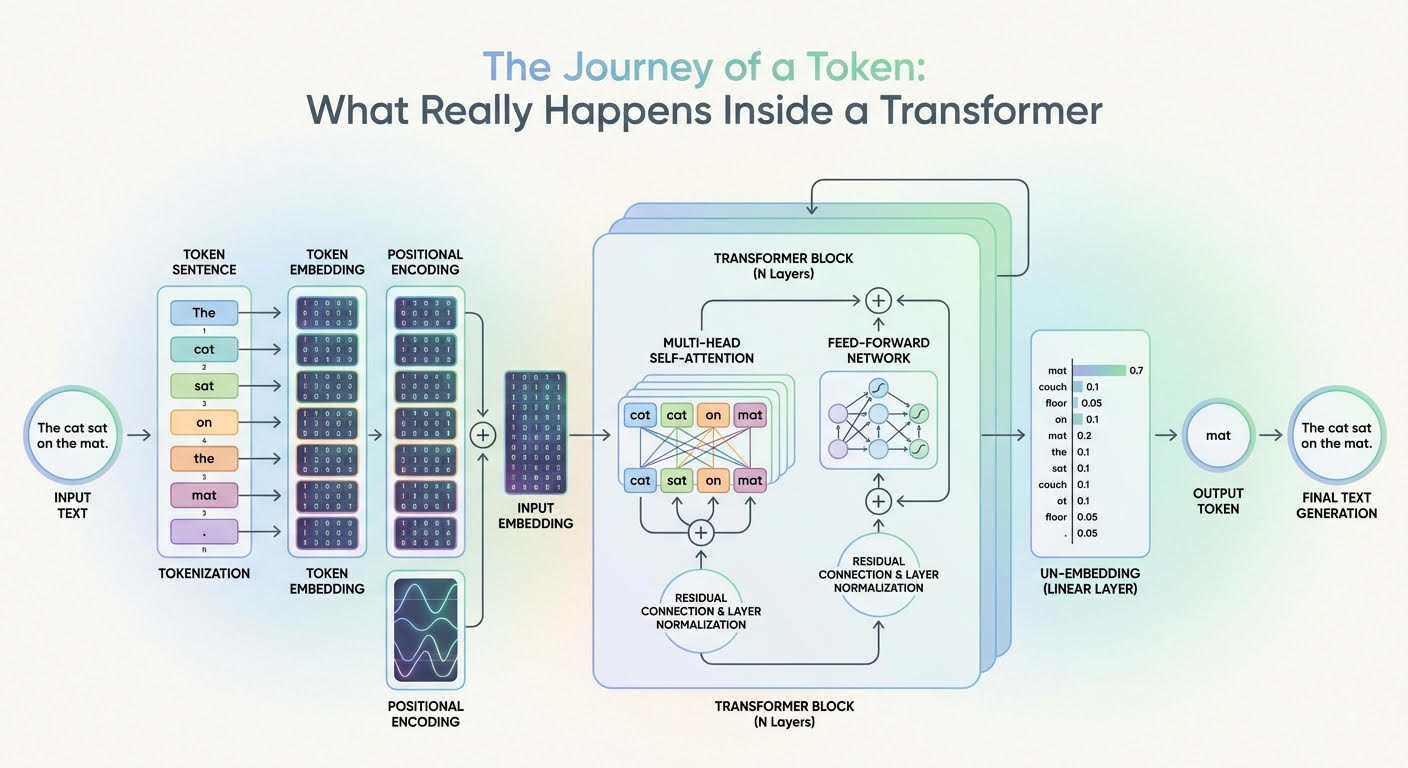
The Journey of a Token: What Really Happens Inside a Transformer
Large language models (LLMs) are based on the transformer architecture, a complex deep neural network whose input is a sequence of token embeddings.
Read More...
Fine-Tuning a BERT Model
This article is divided into two parts; they are: • Fine-tuning a BERT Model for GLUE Tasks • Fine-tuning a BERT Model for SQuAD Tasks GLUE is a benchmark for evaluating natural language...
Read More...Recent posts



















